Read me 1st
Acknowledgements
Introduction

Figure 1. Total cost of one million computing operations over time. Data from Nordhaus Nordhaus_01. Github--Local

Figure 2. Storage cost, in US dollars per Mbyte, of mass market technologies over time. Data from McCallum McCallum_16, floppy and CD-ROM data kindly provided by Davis Davis_01. Github--Local

Figure 3. Growth of time-sharing systems available in the US, with fitted regression line. Data extracted from Glauthier Glauthier_67. Github--Local


Figure 5. Growth of transport and product distribution infrastructure in the USA (underlying data is measured in miles). Data from Grübler et al Grubler_91. Github--Local

Figure 6. Market capitalization of IBM, Microsoft and Apple (upper), and expressed as a percentage of the top 100 listed US tech companies (lower). Data extracted from the Economist website Economist_15. Github--Local

Figure 7. Total annual sales of some of the major species of computers over the last 60 years. Data from Gordon Gordon_87 (mainframes and minicomputers), Reimer Reimer_12 (PCs) and Gartner Gartner_17 (smartphones). Github--Local



Figure 10. Total investment in tangible and intangible assets by UK companies, based on their audited accounts. Data from Goodridge et al Goodridge_14. Github--Local

Figure 11. Quarterly value of newly purchased and own software, and purchased hardware, reported by UK companies as fixed-assets. Data from UK Office for National Statistics Off_Nat_Stat_17. Github--Local



Figure 14. Spectral analysis of World GDP between 1870-2008; peaks around 17 and 70 years. Data from Maddison Maddison_91. Github--Local

Figure 15. Number of unique files and commits first appearing in a given month; lines are fitted regression models of the form: $\mathit{Files}\propto e^{0.03\mathit{months} }$ and $\mathit{Commits}\propto e^{0.022\mathit{months} }$. Data kindly provided by Rousseau Rousseau_20. Github--Local





Human cognition





Figure 25. Probability that rat N1 will press a lever a given number of times before pressing a second lever to obtain food, when the target count is 4, 8, 12 and 16. Data extracted from Mechner Mechner_58. Github--Local




Figure 29. Two objects paired with another object that may be a rotated version. Based on Shepard et al Shepard_71. Github--Local


Figure 31. The five possible ways in which experimenter’s rule and subject’s rule hypothesis can overlap, in the space of all possible rules; based on Klayman et al Klayman_87. Github--Local


Figure 33. Examples of distinct items among visually similar items. The left plot includes an item that has a distinguishing feature (i.e, a vertical line), while the right plot includes an item that is missing a distinguishing feature. Based on displays used by Treisman et al Treisman_85. Github--Local

Figure 34. Continuity&emdash; upper left plot is perceived as two curved lines; Closure&emdash; when the two perceived lines are joined at their end (upper right), the perception changes to one of two cone-shaped objects; Symmetry and parallelism&emdash; where the direction taken by one line follows the same pattern of behavior as another line; Proximity&emdash; the horizontal distance between the dots in the lower left plot is less than the vertical distance, causing them to be perceptually grouped into lines (the relative distances are reversed in the right plot); Similarity&emdash; a variety of dimensions along which visual items can differ sufficiently to cause them to be perceived as being distinct; rotating two line segments by 180°ree; does not create as big a perceived difference as rotating them by 45°ree;. Github--Local


Figure 36. Examples of the three tasks subjects were asked to solve. Left (RV GV): solid red rectangle having same alignment with outline green rectangle, middle (RV RHGV): solid vertical rectangle among solid horizontal rectangles and outlined vertical green rectangles, and right (2 5): digital 2 among digital 5s. Adapted from Palmer et al Palmer_11. Github--Local


Figure 38. The foveal, parafoveal and peripheral vision regions when three characters visually subtend 3°ree;. Based on Schotter et al Schotter_12. Github--Local

Figure 40. Structure of mammalian long-term memory subsystems; brain areas in red. Based on Squire et al Squire_15.

Figure 41. Example object layout, and the corresponding ordered tree produced from the answers given by one subject. Data extracted from McNamara et al McNamara_89. Github--Local

Figure 42. Response time (left axis) and error percentage (right axis) on reasoning task with a given number of digits held in memory. Data extracted from Baddeley Baddeley_09. Github--Local

Figure 43. Major components of working memory: working memory in yellow, long-term memory in orange. Based on Baddeley Baddeley_12. Github--Local

Figure 44. Yes/no response time (in milliseconds) as a function of number of digits held in memory. Data extracted from Sternberg Sternberg_69. Github--Local



Figure 47. Sequencing errors (as percentage), after interruptions of various length (red), including 95% confidence intervals, sequence error rate without interruptions in green; lines are fitted model predictions. Data from Altmann et al Altmann_17. Github--Local

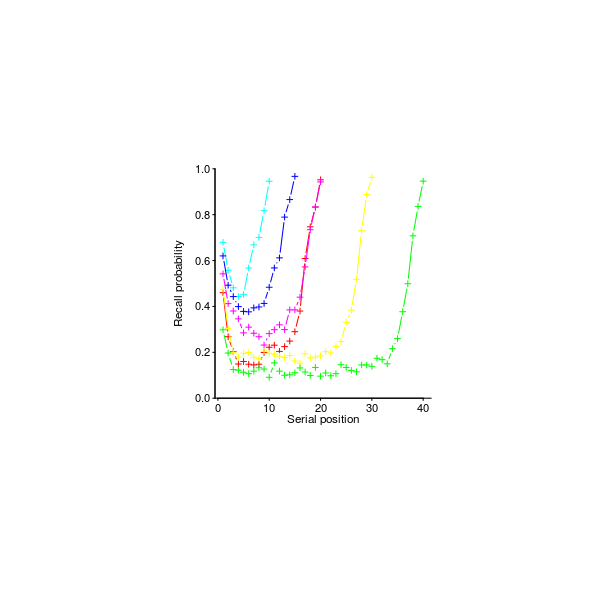
Figure 49. Probability of correct recall of words, by serial presentation order; for lists of length 10, 15 and 20 each word visible for 1, for lists of length 20, 30 and 40 each word visible for 2 seconds. Data from Murdoch Murdoch_62, via Brown Brown_07. Github--Local


Figure 51. Hierarchical clustering of statement recall order, averaged over teachers and students; label names are: program_list-statementkind, where statementkind might be a function header, loop, etc. Data extracted from Adelson Adelson_81. Github--Local




Figure 55. Time taken to solve the same jig-saw puzzle 35 times, followed by a two-week interval and then another 35 times, with power law and exponential fits. Data extracted from Alteneder Alteneder_35. Github--Local

Figure 56. Probability of assigning a stimulus to the correct category, where the category involved: height, position, and a combination of both height and position. Data from Kruschke Kruschke_93. Github--Local

Figure 57. Probability of assigning a stimulus to the correct category; learning the category, followed in block 23 by a change in the characteristics of the learned category. Data from Kruschke Kruschke_96. Github--Local




Figure 61. Time taken by 24 subjects, classified by years of professional experience, to complete successive tasks. Data from Latorre Latorre_14. Github--Local

Figure 62. Elapsed months during which Asimov published a given number of books, with lines for two fitted regression models. Data from Ohlsson Ohlsson_92. Github--Local

Figure 63. Subjects' belief response curves when presented with evidence in the sequences: (upper) positive weak, then positive strong, (middle) negative weak then negative strong, (lower) positive then negative. Based on Hogarth et al Hogarth_92. Github--Local

Figure 64. Lines of code correctly recalled after a given number of 2-minute memorization sessions; actual program in upper plot, scrambled line order in lower plot. Data extracted from McKeithen et al McKeithen_81. Github--Local

Figure 65. One subject’s response time over successive blocks of command line trials and fitted loess (in green). Data kindly provided by Remington Remington_16. Github--Local

Figure 66. Country boundaries (green line) and town locations (red dots). Congruent: straight boundary aligned with question asked, incongruent: meandering boundary and locations sometimes inconsistent with question asked. Based on Stevens et al Stevens_78. Github--Local
Figure 67. Orthogonal representation of shape, color and size stimuli. Based on Shepard Shepard_61.
Figure 68. The six unique configurations of selecting four times from eight possibilities, i.e., it is not possible to rotate one configuration into another within these six configurations. Based on Shepard Shepard_61.

Figure 69. Percentage of correct category answers produced by one subject against boolean-complexity, broken down by number of positive cases needed to define the category used in the question (three colors). Data kindly provided by Feldman Feldman_00. Github--Local
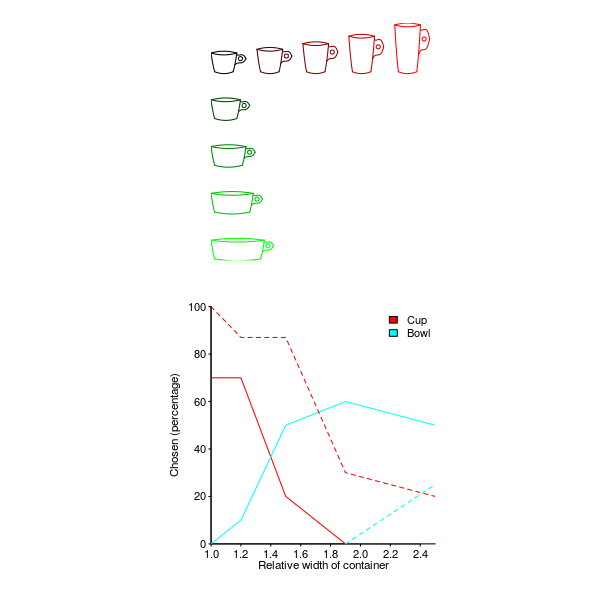
Figure 70. Cup- and bowl-like objects of various widths (ratios 1.2, 1.5, 1.9, and 2.5), and heights (ratios 1.2, 1.5, 1.9, and 2.4), with dashed lines showing neutral context and solid lines food context. The percentage of subjects who selected the term cup or bowl to describe the object they were shown (the paper did not explain why the figures do not sum to 100%, and color was not used in the original). Based on Labov Labov_73. Github--Local

Figure 71. A commercial event involving a buyer, seller, money and goods; as seen from the buy, sell, pay, or charge perspective. Based on Fillmore Fillmore_77. Github--Local




Figure 75. Probability a subject will successfully distinguish a difference between the number of dots displayed, and a specified target number (x-axis is the difference between these two values). Data extracted from van Oeffelen et al van_Oeffelen_82. Github--Local




Figure 79. Min/max range of values (red/blue lines), and best value estimate (green circles), given by subjects interpreting the value likely expressed by statements containing “less than 100” and “more than 100”. Data kindly provided by Cummins Cummins_11. Github--Local


Figure 81. Percentage of incorrect answers to arithmetic problems, given by Canadian and Chinese students, for each operand family value. Data kindly provided by LeFevre LeFevre_97. Github--Local

Figure 82. Estimated proportion (from survey results), and actual proportion of people in a population matching various demographics; line is a fitted regression having the form: $\mathit{lo} _\mathit{Estimated}\propto \gamma\times\mathit{lo} _\mathit{Actual} +(1-\gamma)\times\delta$, where $\gamma$ and $\delta$ are fitted constants; grey line shows estimated equals actual. Data from Landy et al Landy_18. Github--Local


echo=FALSE,results=hide,label=Stewart_analysis,fig=TRUE,align="center">>
Figure 85. Fitted regression model for probability that a subject, who switched answer three times, switches their initial answer when told a given fraction of opposite responses were made by others (x-axis), broken down by confidence expressed in their answer (colored lines). Data kindly provided by Morgan Morgan_12. Github--Local



Figure 88. Subjects' estimate of their ability (x-axis) to correctly answer a question and actual performance in answering on the left scale. The responses of a person with perfect self-knowledge is given by the green line. Data extracted from Lichtenstein et al Lichtenstein_77. Github--Local



Figure 91. Violin plots for actual time to complete problems for each of the 593 participants, sorted by mean solution time; colors to help break up the plots, and white line shows subject mean. Data from Nichols Nichols_19. Github--Local

Figure 92. Mean time for each of 36 subjects to choose between a given number of alternatives (upper), and accuracy rate for a given number of alternatives (lower), data has been jittered; lines are regression fits (yellow shows 95% confidence intervals), and color used for each subject sorted by performance on the two-choice case. Data from Hawkins et al Hawkins_12b. Github--Local
Cognitive capitalism



Figure 95. Number of people employed by major software companies. Data from Campbell-Kelly Campbell-Kelly_04. Github--Local

Figure 96. Company revenue ($millions) against total software development costs; line is a fitted regression model of the form: $\mathit{developmentCosts}\propto 0.19\mathit{Revenue}$. Data from Mulford et al Mulford_16. Github--Local


Figure 98. Development cost (adjusted to 2018 dollars) of computer video games, whose cost was more than $50million. Data from Wikipedia Wiki_Games_18. Github--Local





Figure 103. Bug bounty payer (left) and payee (right) countries (total value $23,632,408). Data from hackerone Hackerone_17. Github--Local



Figure 106. Cumulative percentage of files, from the top 10% largest Java projects, containing a given license (upper line is no license). Data from Vendome et al Vendome_17. Github--Local



Figure 109. The cumulative number of hours worked per week by the 47 individuals involved with one avionics development project; dashed grey lines are straight lines fitted to three individuals. Data from Nichols et al Nichols_18. Github--Local


Figure 111. Percentage of passers-by looking up or stopping, as a function of group size; lines are fitted linear beta regression models. Data extracted from Milgram et al Milgram_69. Github--Local

Figure 112. Hours required to build a car radio after the production of a given number of radios, with break periods (shown in days above x-axis); lines are regression models fitted to each production period. Data extracted from Nembhard et al Nembhard_01. Github--Local

Figure 113. Man-hours required to build a particular kind of ship, at the Delta Shipbuilding yard, delivered on a given date (x-axis). Data from Thompson Thompson_07. Github--Local

Figure 114. Task rating given to members of successive generations of teams; lines are a regression model fitted to the one (red) and five (blue-green) write-up generation sequences. Data from Muthukrishna et al Muthukrishna_13. Github--Local

Figure 115. Ratio of actual to estimated hours of effort to enhance an existing product, for 25 versions of one application. Data from Huijgens et al Huijgens_16. Github--Local

Figure 116. Interval between product announcement date and its promised availability date, against interval between promised date and actual date the product became available; lines are a fitted regression model of the form: $\mathit{A{_}P}\propto e^{0.3-0.1\\\mathit{P{_}P} +0.8\\\sqrt{\mathit{P{_}P} }}$, and a loess fit. Data from Bayus et al Bayus_01. Github--Local



Figure 119. Density plot of the difference between mean team mark and individual mark, broken down by team size. Data from Akdemir et al Akdemir_08. Github--Local


Figure 121. Time taken to publish an RFC having Standard or non-Standard status, for IETF committees having a given percentage of commercial membership (i.e., people wearing suits); lines are a fitted regression model with 95% confidence intervals (red), and a loess fit (blue/green). Data from Simcoe Simcoe_13. Github--Local

Figure 122. Percentage of developers, employed by given companies, working on OpenStack at the time of a release (x-axis). Data from Teixeira et al Teixeira_15. Github--Local



Figure 125. Average effort (in days) used to fix a fault experienced in a given phase (x-axis) caused by a mistake that had been introduced in an earlier phrase (colored lines), introduced in an earlier phase (total of 38,120 defects in projects at Hughes Aircraft). Data extracted from Willis et al Willis_98. Github--Local






Figure 131. Rates at which product sales are made on Gumroad at various prices; lines join prices that differ in 1¢s;, e.g., $1.99 and $2. Data from Nichols Nichols_13. Github--Local

Figure 132. Sales of game software (solid lines) for the corresponding three major seventh generation hardware consoles (dotted lines). Data from VGChartz VGChartz_17. Github--Local



Figure 135. Facebook’s ARPU and cost of revenue per user. Data from Facebook’s 10-K filings Facebook_14Facebook_16. Github--Local


Figure 137. Number of applications in the Android market and Amazon App Store, during 2012, containing a given number of advertising libraries (line is a fitted Negative Binomial distribution). Data from Shekhar et al Shekhar_12. Github--Local
Ecosystems

Figure 138. Connections between the 164 companies that have Apps included in the Microsoft Office365 Marketplace (Microsoft not included); vertex size is an indicator of the number of Apps a company has in the Marketplace. Data kindly provided by van Angeren van_Angeren_16. Github--Local





Figure 143. Mobile phone operating system shipments, as percentage of total per year. Data from Reimer Reimer_12 (before 2007), and Gartner Gartner_17 (after 2006). Github--Local

Figure 144. Reported number of worldwide software industry mergers and acquisitions (M&A), per year. Data from Solganick Solganick_16. Github--Local

Figure 145. Average monthly donations received by 470 Github repositories using Patreon and OpenCollective. Data from Overney et al Overney_20. Github--Local


Figure 147. Performance, in MIPS, against price of 106 computer systems available in 1981. Data from Ein-Dor Ein-Dor_85. Github--Local

Figure 148. Total sales of various kinds of processors. Data from Hilbert et al Hilbert_11. Github--Local


Figure 150. Survival curve for GCC’s support for distinct cpus and non-processor specific compile-time options; with 95% confidence intervals. Data extracted from gcc website GCC_opts_19. Github--Local

Figure 151. Maximum speed achieved by vehicles over the surface of the Earth, and in the air, over time. Data from Lienhard Lienhard_06. Github--Local

Figure 152. Number of transistors, frequency and SPEC performance of cpus when first launched. Data from Danowitz et al Danowitz_12. Github--Local

Figure 153. Number of major forks of projects per year, identified using Wikipedia during August 2011. Data from Robles et al Robles_12b. Github--Local



Figure 156. Number of websites running a given version of PHP on the first day of February, 2016 and 2017, ordered by PHP version number. Data kindly provided by Ruohonen Ruohonen_17. Github--Local

Figure 157. Decade in which newly designed US Air Force aircraft first flew, with colors indicating current operational status. Data from Echbeth el at Eckbreth_11. Github--Local

Figure 158. Mean age of installed mainframe computers, 1968-1983. Data from Greenstein Greenstein_94. Github--Local

Figure 159. Survival curve of Linux distributions derived from five widely-used parent distributions (identified in legend). Data from Lundqvist et al Lundqvist_12. Github--Local

Figure 160. Percentage share of Android market, of a given release, by days since its launch. Data from Villard Villard_15. Github--Local



Figure 163. Number of US companies manufacturing automobiles and PCs, over the first 30-years of each industry. Data extracted from Mazzucato Mazzucato_01. Github--Local

Figure 164. Retail prices of Model T Fords and sales volume. Data from Hounshell Hounshell_84. Github--Local







Figure 171. Total U.S. revenue from sale of computer systems and data processing service industry revenue. Data from Phister Phister_79 table II.1.20 and II.1.26. Github--Local

Figure 172. Total yearly spend on their own software by the 21 industry sectors in the UK, reported by companies as fixed-assets. Data from UK Office for National Statistics Off_Nat_Stat_17. Github--Local




Figure 176. Number of new UK companies registered each month, whose SIC description includes the word software (45,422 entries) or computer (18,001 entries). Data extracted from OpenCorporates OpenCorporates_15. Github--Local

Figure 177. Connections between companies in a Dutch software business network. Data kindly provided by Crooymans Crooymans_15. Github--Local

Figure 178. Number of people employed in the 12 computer occupation codes assigned by the U.S. Census Bureau during 2014, stratified by ages bands (main peak is the total, “Software developers, applications and system software” is the largest single percentage; see code for the identity of other occupation codes). Data from Beckhusen Beckhusen_16. Github--Local


Figure 180. Sorted list of total amount awarded by bug bounties to individual researchers, based on two datasets downloaded from HackerOne. Data from Zhao et al Zhao_15 and Maillart et al Maillart_17. Github--Local



Figure 183. Number of pdf files created using a given version of the portable document format appearing on sites having a .uk web address between 1996 and 2010. Data from Jackson Jackson_12. Github--Local


Figure 185. Number of Unix processes executing for a given number of seconds, on a 1995 era computer. Data from Harchol-Balter et al Harchol-Balter_95. Github--Local



Figure 188. Lines of code written in the 32 programming languages appearing in the source code of the 13 major Debian releases between 1998 and 2019. Data from the Debsources developers Debsources_dev_19. Github--Local


Figure 190. Number of monthly developer job related tweets specifying a given language. Data kindly provided by Destefanis Destefanis_14. Github--Local

Figure 191. Normalised percentage of 34 language tags associated with questions appearing on Stack Overflow in each month. Data extracted from Stack Overflow website SO_trends_19. Github--Local



Figure 194. Number of Android/Ubuntu (1.1 million apps)/(71,199 packages) linking to a given POSIX function (sorted into rank order). Data from Atlidakis et al Atlidakis_16. Github--Local


Figure 196. Survival curve of packages included in 10 official Debian releases, and inclusion of the same release of a package; dashed lines are 95% confidence intervals. Data from Caneill et al Caneill_14. Github--Local


Figure 198. Survival curves for Debian package lifetime and interval before a package contains its first dependency conflict; dashed lines are 95% confidence intervals. Data from Drobisz et al Drobisz_15. Github--Local



Figure 201. Number of gcc compiler options, for all supported versions, relating to languages and the process of building an executable program. Data extracted from gcc website GCC_opts_19. Github--Local

Figure 202. Words in Intel x86 architecture manuals, and code-points in Unicode Standard over time. Data for Intel x86 manual kindly provided by Baumann Baumann_16. Github--Local
Projects



Figure 205. Annual development cost and lines of code delivered to the US Air Force between 1960 and 1986. Data extracted from NeSmith NeSmith_86. Github--Local


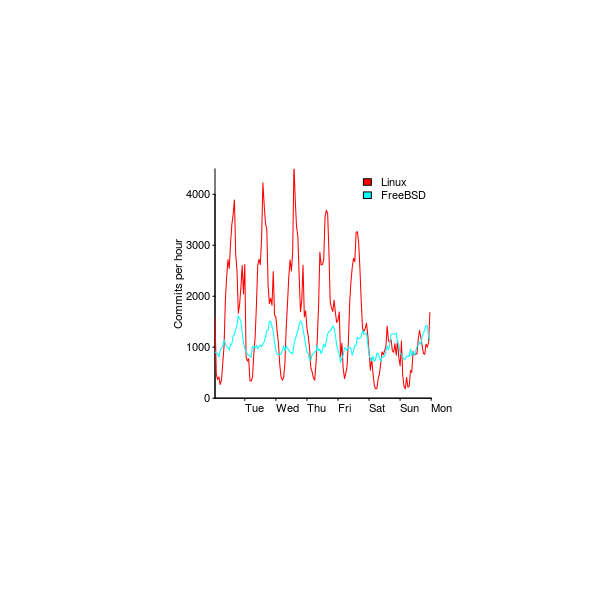
Figure 208. Commits within a particular hour and day of week for Linux and FreeBSD. Data from Eyolfson et al Eyolfson_11. Github--Local

Figure 209. Survival rate of 214 projects, by development stage, with 95% confidence intervals. Data from McManus et al McManus_07. Github--Local

Figure 210. Estimated and Actual effort for internal and external projects, lines are fitted regression models; both lines are fitted regression models of the form: $\mathit{Actual}\propto \mathit{Estimate}^a$, where $a$ takes the value 0.9 or 1.1. Data from Moløkken-Østvold et al Molokken_Ostvold_04. Github--Local

Figure 211. Bids made by 19 estimators from the same company (divided by grey line into the two experimental groups). Data from Jørgensen et al Jorgensen_04c. Github--Local


Figure 213. Mean number of years experience of each team against estimated project code, with fitted regression models; broken down by teams containing one or more members who have had similar project experience, or not. Data from Mcdonald Mcdonald_05. Github--Local

Figure 214. Estimated and actual project implementation effort; 49 web implementation tasks (blue), and 145 tasks performed by an outsourcing company (red). Data from Jørgensen Jorgensen_04b and Kitchenham et al Kitchenham_02. Github--Local

Figure 215. Two estimates (in work hours), made by seven subjects, for each of six tasks. Data from Grimstad et al Grimstad_07. Github--Local





Figure 220. Estimated project cost from 12 estimating models. Data from Mohanty Mohanty_81. Github--Local


Figure 222. Function points and corresponding normalised costs for 149 projects from one large institution; line is a fitted regression model of the form: $\mathit{Cost}\propto \mathit{Function{_}Points}^{0.75}$. Data extracted from Kampstra el al Kampstra_09b. Github--Local

Figure 223. Cost per requirement, function point and story point for two projects, over 13 monthly releases. Data from Huijgens Huijgens_13. Github--Local

Figure 224. Estimated effort to implement 24 story-points and corresponding COSMIC function point; line is a fitted regression model of the form: $\mathit{CosmicFP}\propto \mathit{storyPoint}^{0.6}$, with 95% confidence intervals. Data from Commeyne et al Commeyne_16. Github--Local

Figure 225. Mean LOC against standard deviation of LOC, for multiple implementations of seven distinct problems; line is a fitted regression model of the form: $\mathit{Standard{_}deviation}\propto \mathit{SLOC}$. Data from: Anda et al Anda_09, Jørgensen Jorgensen_16b, Lauterbach Lauterbach_87, McAllister et al McAllister_89, Selby et al Selby_85, Shimasaki et al Shimasaki_80, van der Meulen van_der_Meulen_07. Github--Local


Figure 227. IBM’s profit margin on all System 360s sold in 1966, by system memory capacity in kilobytes; monthly rental cost during 1967 in parentheses. Data from DeLamarter DeLamarter_88. Github--Local


Figure 229. Number of requirements and corresponding lines of manually created source code, for each team (colors denote language used). Data from Prechelt Prechelt_07 Github--Local



Figure 232. Phase during which work on a given activity of development was actually performed, average percentages over 13 projects. Data from Zelkowitz Zelkowitz_87. Github--Local


Figure 234. Percentage distribution of effort across design/coding/testing for 10 ICL projects (red), 11 BT projects (green), 11 space projects (blue) and 12 defense projects (purple). Data from Kitchenham et al Kitchenham_85 and Graver et al Graver_77. Github--Local

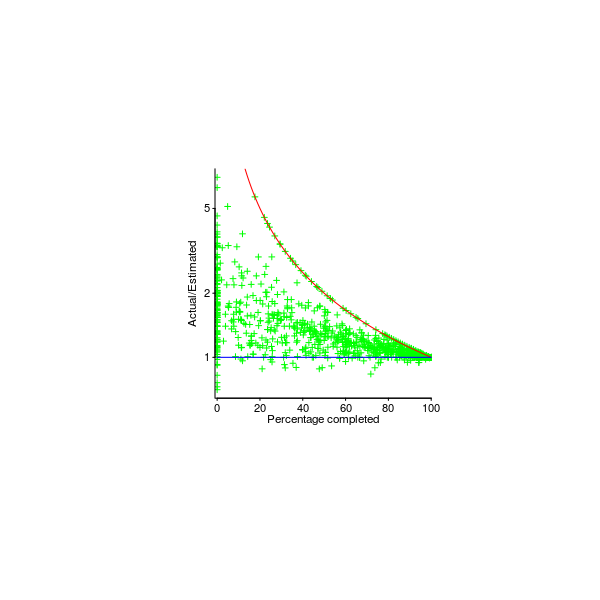


Figure 238. Percentage change in 882 estimated delivery dates, announced at a given percentage of the estimated elapsed time of the corresponding project, for 121 projects (red is a loess fit); blue line is a density plot of percentage estimated duration when the estimate was made. Data kindly provided by Little Little_06. Github--Local

Figure 239. Percentage of work packages having a given lead time that are completed within a given duration; colored lines are work packages having the same estimated lead time. Data extracted from van Oorschot et al van_Oorschot_05. Github--Local



Figure 242. Average value assigned to requirements (red) and one standard deviation bounds (blue) based on omitting one stakeholder’s priority value list. Data from Regnell et al Regnell_01. Github--Local

Figure 243. Number of features whose implementation took a given number of elapsed workdays; red first 650-days, blue post 650-days, green lines are fitted zero-truncated negative binomial distributions. Data kindly supplied by 7Digital 7Digital_12. Github--Local

Figure 244. Average number of days taken to implement a feature, over time; smoothed using a 25-day rolling mean. Data kindly supplied by 7Digital 7Digital_12. Github--Local

Figure 245. Number of feature developments started on a given work day (red new features, green bugs fixes, blue ratio of two values; 25-day rolling mean). Data kindly supplied by 7Digital 7Digital_12. Github--Local






Figure 251. Number of identifiers renamed, each month, in the source of Eclipse-JDT; version released on given date shown. Data from Eshkevari et al Eshkevari_11. Github--Local

Figure 252. Percentage of commits outstanding against percentage the time remaining before deployment, for 18 releases; blue/green transition is the feature freeze date, red line shows a constant commit rate. Data kindly provided by Laukkanen Laukkanen_17. Github--Local

Figure 253. Number of failed jobs in Travis CI builds involving a given number of jobs (points have been jittered); line is a loess fit. Data from Gallaba et al Gallaba_18. Github--Local

Figure 254. Survival curve of IT outsourcing suppliers continuing to work for 2,382 Credit Unions. Data kindly provided by Peukert Peukert_10. Github--Local


Figure 256. Number of projects making use of a given number of different languages in a sample of 100,000 GitHub project. Data kindly provided by Bissyande Bissyande_13. Github--Local

Figure 257. Number of tasks worked on by a given number of developers. Data from Nichols et al Nichols_18 and Jones et al Jones_19a. Github--Local

Figure 258. Number of days before planned product ship date, against number of full time engineers, for each of the 63 months since the project started (numbers show months since project started). Data from Jackson Jackson_89. Github--Local


Figure 260. Time taken by groups of different sizes to manually assembly a product, over multiple trials; lines are fitted regression models of the form: $\mathit{Time}\propto ~ \frac{0.5-0.2\log(\mathit{Repetitions} )}{\mathit{Group{_}size} }-0.1\log(\mathit{Repetitions} )$. Data kindly provided by Peltokorpi et al Peltokorpi_19. Github--Local

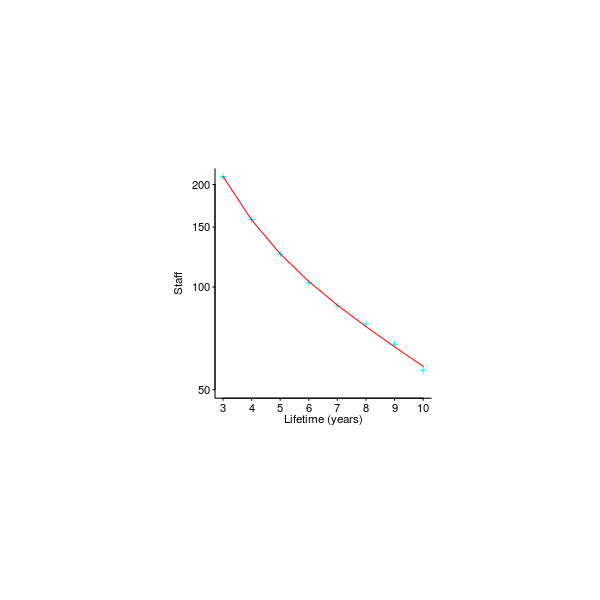
Figure 262. Average number of staff required to support renewal of code having a given average lifetime (green); blue/red lines show fitted biexponential regression model. Data extracted from Elliott Elliott_77. Github--Local

Figure 263. Age of systems, developed using one of two methodologies, and corresponding monthly maintenance effort, lines are loess regression fits. Data extracted from Dekleva Dekleva_92. Github--Local






Figure 269. Density plot of interval between a patch passing review and being accepted by a maintainer, and interval between a maintainer pushing the patch to Linus Torvalds, and it being accepted into the blessed mainline (only patches accepted by Torvalds included). Data from Jiang et al Jiang_13. Github--Local

Figure 270. Evolution of the number of tables in the Mediawiki and Ensembl project database schema. Data from Skoulis Skoulis_13. Github--Local

Figure 271. Survival curve for tables in Wikimedia and Ensembl database schema, with 95% confidence intervals. Data from Skoulis Skoulis_13. Github--Local

Reliability



Figure 275. Accuracy of the value returned by the $\cos$ instruction on an Intel Core i7, for 52,521 argument values close to $\frac{\pi}2$. Data kindly provided by Duplichan Duplichan_13. Github--Local




Figure 279. Mean percentage likelihood of (translated) statements containing a probabilistic term; one colored line per country. Data from Budescu et al Budescu_14. Github--Local


Figure 281. Survival curves of the two most common warnings reported by Splint in Samba and Squid, where survival was driven by code changes and not fixing a reported fault; with 95% confidence intervals. Data from De Penta et al Di_penta_09. Github--Local



Figure 284. Number of incidents reported for each of 800 applications installed on over 120,000 desktop machines; line is fitted regression model. Data from Lucente Lucente_15. Github--Local


Figure 286. Number of accesses to memory address blocks, per 100,000 instructions, when executing
gzip on two different input files. Data from Brigham Young Brigham_Young via Feitelson. Github--Local








Figure 295. Violin plots of likelihood (local y-axis) that an add-one perturbation at a (normalised) program location will not change the output behavior. Data from Danglot et al Danglot_18. Github--Local

Figure 296. Predicted growth, with 95% confidence intervals, in the number of new crash fault experiences in the 2003, 2007 and 2010 releases of Microsoft Office. Data from Kaminsky et al Kaminsky_11. Github--Local

Figure 297. Number of crashes traced to the same executable location (sorted by number of crashes), in the 2003, 2007 and 2010 releases of Microsoft Office; lines are fitted biexponential regression models. Data from Kaminsky et al Kaminsky_11. Github--Local



Figure 300. Lines of source in early versions of Firefox, broken down by the version in which it first appears. Data extracted from Massacci et al Massacci_11. Github--Local


Figure 302. End-user usage of code originally written for Firefox version 1.0, by major released versions (in units of LOC*Users); red points show sum over all versions. Based on data from Jones Jones_13 and extracted from Massacci et al Massacci_11. Github--Local

Figure 303. Total number of implementations in each of 36 equivalence classes, plus both first and last competitor submissions. Data from van der Meulen et al van_der_Meulen_04. Github--Local


Figure 305. Cumulative number of potential defects logged against the POSIX standard, by defect classification. Data kindly provided by Josey OpenGroup_17. Github--Local

Figure 306. Ranked occurrences of compiler messages generated by student submitted Java and Python programs. Data from Pritchard Pritchard_15. Github--Local

Figure 307. Fraction of mutated programs, in various languages, that successfully compiled/executed/produced the same output. Data from Spinellis et al Spinellis_12. Github--Local


Figure 309. Normalized number of commits (i.e., each maximum is 100), made to address fault reports, involving a given number of files in five software systems; grey line is representative of regression models fitted to each project, and has the form: $\mathit{Commits}\propto \mathit{Files}^{-2.1}$. Data from Zhong et al Zhong_15 via M. Monperrus. Github--Local

Figure 310. Percentage of insertions/modifications of a given number of lines resulting in a reported fault; lines are fitted beta regression models of the form: $\mathit{percent{_}faultReports}\propto \log(\mathit{Lines} )$. Data from Purushothaman et al Purushothaman_05. Github--Local

Figure 311. Survival curve (with 95% confidence bounds) of time to fix vulnerabilities reported in
npm packages (Base) and time to update a package dependency (Depend) to a corrected version (i.e., not containing the reported vulnerability); for vulnerabilities with severity high and medium. Data from Decan et al Decan_18. Github--Local

Figure 313. For systems 2 and 18, number of uptime intervals, binned into 10 hour intervals, red lines are both fitted negative binomial distributions. Data from Los Alamos National Lab (LANL). Github--Local


Figure 315. Reported time taken to correct 7,095 mistakes (in one project), broken down by phase the mistake was introduced/corrected (y-axis), against number of phases between introduction/correction (x-axis); lines are fitted regression models of the form: $\mathit{Fix{_}time}\propto e^{\sqrt{\mathit{phase{_}sep} }}$, with fix times less than 1, 5 and 10-minutes excluded. Data from Nichols et al Nichols_18. Github--Local

Figure 316. Number of vulnerabilities found using black-box testing, and manual code review of nine implementations of the same specification. Data from Finifter Finifter_13b. Github--Local

Figure 317. Fraction of usability problems found by a given number of subjects/evaluations in 12 system evaluations; lines are fitted regression model for each system. Data extracted from Nielsen et al Nielsen_93. Github--Local


Figure 319. Number of faults experienced per unit of testing effort, over a given number of weeks (each normalised to sum to 100). Data from Stikkel Stikkel_06. Github--Local

Figure 320. Statement coverage achieved by the respective program’s test suite (data on the sixth program was not usable). Data from Marinescu et al Marinescu_14. Github--Local

Figure 321. Violin plots of percentage of regular expression components having a given coverage, (measured using the nodes and edges of the DFA representation of the regular expression, broken down by the match failing/succeeding) for 15,096 regular expressions, when passed the corresponding project test input strings. Data kindly provided by Wang Wang_18b. Github--Local


Figure 323. Statement coverage against branch coverage for 300 or so Java projects; colored lines are fitted regression models for three program sizes (see legend), equal value line in grey. Data from Gopinath et al Gopinath_14. Github--Local


Figure 325. Basic-block coverage against branch coverage for a 35 KLOC program; lines are a regression fit (red) and $\mathit{Decision} =\mathit{Block}$ (grey). Data from Gokhale et al Gokhale_06. Github--Local

Figure 326. Fraction of basic-blocks executed by a given number of tests, for 20 implementations using three test suites. . Data from McAllister et al McAllister_89. Github--Local

Figure 327. Statement coverage against mutants killed for 300 or so Java projects; colored lines are fitted regression models for three program sizes, equal value line in grey. Data from Gopinath et al Gopinath_14. Github--Local

Figure 328. Unit cost of a missile, developed for the US military, against the number of development test flights carried out, with fitted power law. Data extracted from Augustine Augustine_97. Github--Local
Source code

Figure 329. Composite image of brain areas active when 30 subjects categorized Java code snippets; colored scale based on t-value of the decoding accuracy of source code categories from the MRI signals. Image from Ikutani et al Ikutani_20.


Figure 331. Fraction of files in high-level categories for 23,715 repositories containing a given number of files (averaged over all repositories containing a given number of files). Data from Pfeiffer Pfeiffer_20. Github--Local

Figure 332. Number of source files, methods, and lines of code within methods, contained in each of 13,103 Java projects; lines are kernel density plots. Data kindly provided by Landman Landman_16. Github--Local

Figure 333. Number of files and lines of code in 3,782 projects hosted on Sourceforge. Data from Herraiz Herraiz_08. Github--Local

Figure 334. Percentage of call instructions contained in code generated from the same C source, against call execution percentage for various processors; grey line is fitted regression model. Data from Davidson et al Davidson_89b. Github--Local


Figure 336. Probability that a worker having a given ability (x-axis) will correctly answer a given question (numbered colored lines); fitted using item response theory. Data from Chapman et al Chapman_17. Github--Local


Figure 338. Lines of code, Halstead’s volume and McCabe’s cyclomatic complexity of the 62,365 C functions containing at least 10 lines, in Linux version 2.6.9; fitted regression lines have the form: $\mathit{Halstead{_}volume}\propto \mathit{KLOC}^{1.1}$ and $\mathit{McCabe{_}complexity}\propto \mathit{KLOC}^{0.8}$. Data from Israeli et al Israeli_10. Github--Local


Figure 340. A clustering of the 2,664 files containing from/to method calls in the
gfx module of Firefox version 20. Data kindly provided by Almossawi Almossawi_13. Github--Local
Figure 341. Phylogenetic tree of 58 folktales, based on 72 story characteristics; 18 classified as ATU 333 (red), 20 as ATU 123 (blue), and 20 unclassified (green). Data from Tehrani Tehrani_13. Github--Local



Figure 344. Number of methods/functions containing a given number of source lines; 17.6M methods, 6.3M functions. Data kindly provided by Landman Landman_16. Github--Local



Figure 347. Two sentences, with their dependency representations; upper sentence has total dependency length six, while in the lower sentence it is seven. Based on Futrell et al Futrell_15. Github--Local

Figure 348. One sentence containing four, and the other eight propositions, along with their propositional analyses. Based on Kintsch et al Kintsch_73. Github--Local

Figure 349. Mean reading time (in seconds) for sentences containing a given number of propositions, and as a function of the number of propositions recalled by subjects; with fitted regression models. Data extracted from Kintsch et al Kintsch_73. Github--Local

Figure 350. Subject confidence level, on a one to five scale (yes positive, no negative), of having previously seen a sentence containing a given number of idea units (experiment 2 was a replication of experiment 1, plus extra sentences). Data extracted from Bransford et al Bransford_71. Github--Local

Figure 351. Percentage of false-positive recognition errors for biographies having varying degrees of thematic relatedness to the famous person, in before, after, famous, and fictitious groups. Data extracted from Dooling et al Dooling_77. Github--Local

Figure 352. Percentage of correct responses in a reading comprehension test, for subjects having a given reading span, using the pronoun reference questions as a function of the number of sentences (x-axis) between the pronoun and the referent noun. Data extracted from Daneman et al Daneman_80. Github--Local

Figure 353. Lines of code (as a percentage of all lines of code in the language measured) appearing in C functions and Java methods containing a given number of lines of code (upper); cumulative sum of SLOC percentage (lower). Data kindly provided by Landman Landman_16. Github--Local


Figure 355. Time taken by subjects to read a page of text, printed with a particular orientation, as they read more pages (initial experiment and repeated after one year); with fitted regression lines. Results are for the same six subjects in two tests more than a year apart. Based on Kolers Kolers_76. Github--Local

Figure 356. Mean response time for each of 17 segments; the regression line fitted to segments 2-15 has the form: $\mathit{Response{_}time}\propto e^{-0.1\mathit{Segment} }$. Data extracted from Lewicki et al Lewicki_88. Github--Local

Figure 357. Percentage occurrence of kinds of source changes (in rank order), with fitted exponentials over a range of ranks (red lines). Data kindly provided by Martinez Martinez_13. Github--Local

Figure 358. Percentage of function definitions declared to have a given number of parameters in: embedded applications, and the translated form of a sample of C source code. Data for embedded applications kindly supplied by Engblom Engblom_99a, C source code sample from Jones Jones_05a. Github--Local
Figure 359. Three versions of the source of the same program, showing identifiers, non-identifiers and in an anonymous form; illustrating how a reader’s existing knowledge of English word usage can reduce the cognitive effort needed to comprehend source code. Based on an example from Laitinen Laitinen_95.




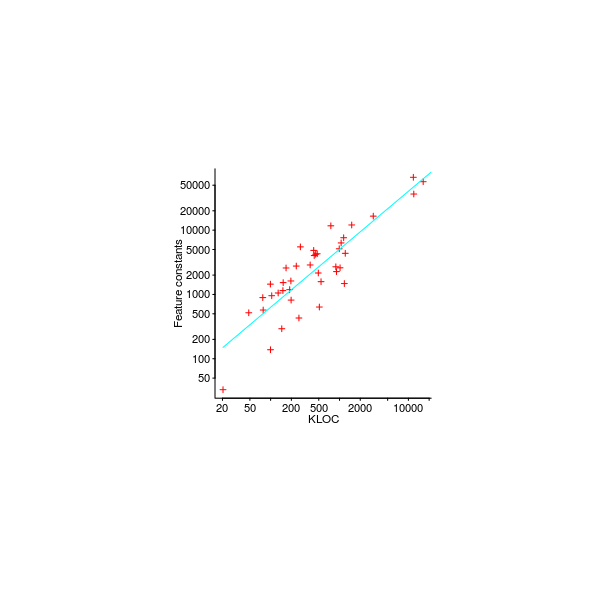


Figure 366. Cumulative percentage of configuration options impacting a given number of source files in the Linux kernel. Data kindly provided by Ziegler Ziegler_16. Github--Local



Figure 369. Fraction of a project’s token sequences, containing a given number of tokens, that appear more than once in the projects' Java source (for 2,637 projects); the yellow line has the form: $\mathit{fraction}\propto a-b*\log(\mathit{seq{_}len} )$, where$a$ and $b$ are fitted constants. Data from Lin et al Lin_17. Github--Local


Figure 371. Number of reintroduced line sequences having a given difference in revision number between deletion and reintroduction (upper), and number of reintroduced line sequences containing a given number of lines (lower); the fitted regression lines have the form: $\mathit{Occurrence}\propto \mathit{NumLines}^{-1.4}e^{0.1\log(\mathit{NumLines})^2}$ and $\mathit{Occurrences}\propto \mathit{NumLines}^{-1.7}$. Data kindly provided by Kamiya Kamiya_11. Github--Local

Figure 372. The Berlin and Kay Berlin_69 language color hierarchy. The presence of any color term in a language implies the existence, in that language, of all terms below it. Papuan Dani has two terms (black and white), while Russian has eleven (Russian may also be an exception in that it has two terms for blue.) Github--Local
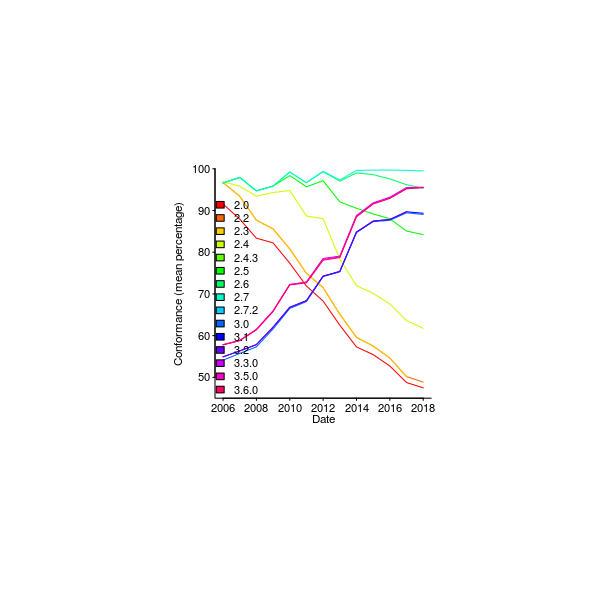




Figure 377. The number of dynamic statements, LOC and methods against total number of those constructs appearing in 28 Ruby programs; lines are power law regression fits. Data from Rodrigues et al Rodrigues_18. Github--Local


Figure 379. Percentage of conditional expressions, in 63 Java programs, containing a given number of clauses; one fitted regression model has the form: $\mathit{Num{_}conditions}\propto e^{ \mathit{Num{_}predicates}\times(\log(\mathit{SLOC})-0.6\log(\mathit{Files})-11)}$, where each variable is the total for a program’s source. Data from Durelli et al Durelli_16. Github--Local

Figure 380. Number of
try blocks whose code might raise a given number of exceptions; fitted regression models have the form: (lower) $\mathit{Num{_}tryBlocks}\propto \mathit{Possible{_}exceptions}^{-0.22}$ and (upper) $\mathit{Num{_}tryBlocks}\propto 7300 e^{-1.4\mathit{Possible{_}exceptions} } +1100 e^{-0.21\mathit{Possible{_}exceptions} }$. Data from de Pádua et al de_Padua_17. Github--Local
Figure 381. Yearly occurrence of number words (e.g., "one", "twenty-two"), averaged over each year since 1960, in Google’s book data for three languages. Data kindly provided by Piantadosi Piantadosi_14. Github--Local



Figure 384. Number of functions defined with a given number of parameters in the C source of four projects; solid lines function body did not access global variables, dashed lines function body accessed global variables. Data from Gonzaga Gonzaga_15. Github--Local




Figure 388. Number of function calls, against corresponding number of calls containing callbacks and anonymous callbacks, in 130 Javascript programs; lines are fitted regression models of the form: $\mathit{allCallbacks}\propto \mathit{allCalls}^{0.86}$ and $\mathit{anonCallbacks}\propto \mathit{allCalls}^{0.8}$, respectively. Data from Gallaba et al Gallaba_15. Github--Local

Figure 389. Number of global variables against lines of code over 48 releases of three systems written in C. Data kindly provided by Neamtiu Neamtiu_05. Github--Local
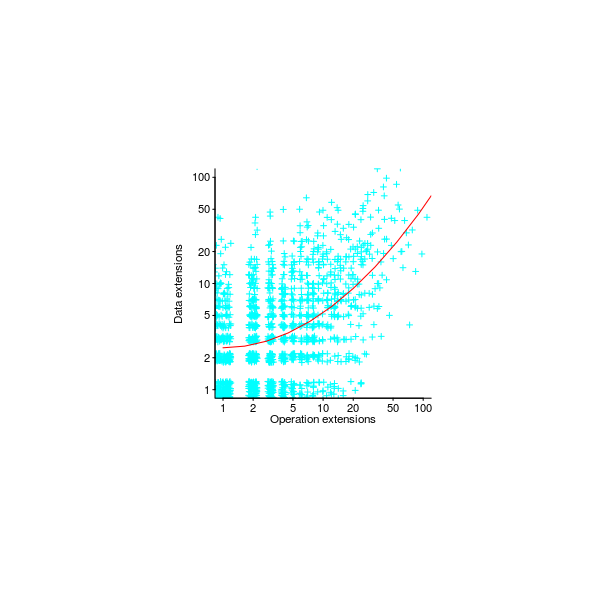



Figure 393. Dependencies between the Java packages in various versions of ANTLR. Data from Al-Mutawa Al-Mutawa_13. Github--Local

Figure 394. Fraction of source in 130 releases of Linux (x-axis) that originates in an earlier release (y-axis). Data extracted from png file kindly supplied by Matsushita Livieri_07. Github--Local

Figure 395. Number of functions in Evolution modified a given number of times (upper), and modified by a given number of different people (lower); red line is a fitted bi-exponential, green/blue lines are the individual exponentials. Data from Robles et al Robles_12a. Github--Local

Figure 396. Number of functions (in Evolution) modified a given number of times, broken down by number of authors; lines are a fitted regression model. Data from Robles et al Robles_12a. Github--Local

Figure 397. Density plot of the time interval, in hours, between each modification of the functions in Evolution and Apache. Data from Robles et al Robles_12a. Github--Local
Stories told by data



Figure 400. Years of professional experience in a given language for experimental subjects. Data from Prechelt Prechelt_07. Github--Local


Figure 402. Various measurements of work performed implementing the same functionality, number of lines of Haskell and C implementing functionality, CFP (COSMIC function points; based on user manual) and length of formal specification. Data kindly provided by Staples Staples_13. Github--Local

Figure 403. Effort, in hours (log scale), spent in various development phases of projects written in Ada (blue) and Fortran (red). Data from Waligora et al Waligora_95. Github--Local
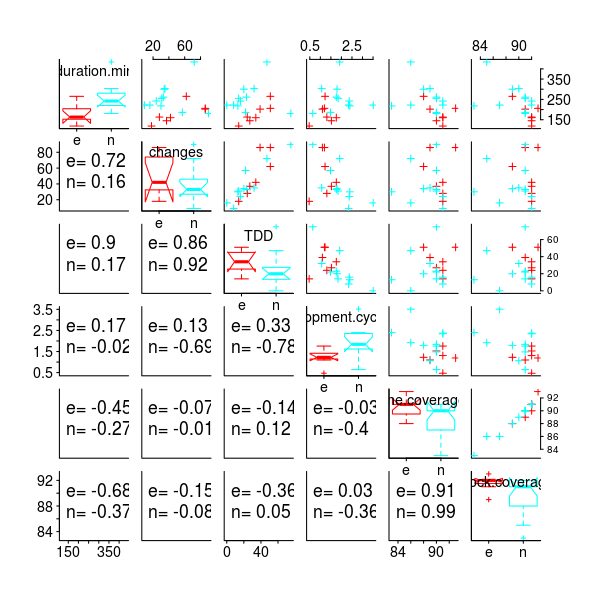

Figure 405. Correlations between pairs of attributes of 12,799 Github pull requests to the Homebrew repo, represented using numeric values and pie charts. Data from Gousios et al Gousios_14. Github--Local

Figure 406. Hierarchical cluster of correlation between pairs of attributes of 12,799 Github pull requests to the Homebrew repo. Data from Gousios et al Gousios_14. Github--Local



Figure 409. Relative clock frequency of cpus when first launched (1970 == 1). Data from Danowitz et al Danowitz_12. Github--Local







Figure 416. Number of lines added to glibc each week. Data from González-Barahona et al Gonzalez-Barahona_14. Github--Local



Figure 419. Time taken for developers to debug various programs using batch processing or online (i.e., time-sharing) systems. Data kindly provided by Prechelt Prechelt_99a. Github--Local

Figure 420. Pairs of languages used together in the same GitHub project with connecting line width, color and transparency related to number of occurrences. Data kindly supplied by Bissyande Bissyande_13. Github--Local


Figure 422. Alluvial plot of relative prioritization order of selection and application of Github pull requests. Data from Gousios et al Gousios_15a. Github--Local


Figure 424. Contour plot of number of sessions executed on a computer having a given processor speed and memory capacity. Data kindly provided by Thereska Thereska_10. Github--Local





Figure 429. Estimated market share of Android devices by brand and product, based on downloads from 682,000 unique devices in 2015. Data from OpenSignal OpenSignal_15. Github--Local


Figure 431. Throughput when running the SPEC SDM91 benchmark on a Sun SPARCcenter 2000 containing 8 CPUs, with the predictions from three fitted queuing models. Data from Gunther Gunther_05. Github--Local



Figure 434. Percentage share of Android market by successive Android releases, by individual version (top) and by date (lower); pastell colors on left and bold on right. Data from Villard Villard_15. Github--Local





Probability


Figure 441. Number of subjects rating more than eight jokes, with fitted bi-exponential model; line is a fitted regression model of the form: $\mathit{Subjects}\propto 4200 e^{-0.09\mathit{Jokes} } +650 e^{-0.02\mathit{Jokes} }$. Data from Goldberg et al Goldberg_01. Github--Local

Figure 442. The relationship between words for tracts of trees in various languages. The interpretation given to words (boundary indicated by the zigzags) in one language may overlap that given in other languages. Adapted from DiMarco et al DiMarco_93. Github--Local
Figure 443. Relationships between commonly used discrete and continuous probability distributions.




Figure 448. Reading rate for text printed using a serif (blue) and sans-serif (red) font, data has been normalised and displayed as a density. Data from Veytsman et al Veytsman_12. Github--Local

Figure 449. Probability, with p-value < 0.05, that
shapiro.test correctly reports that samples drawn from various distributions are not drawn from a Normal distribution, and probability of an incorrect report when the sample is drawn from a Normal distribution; 1,000 replications for each sample size. Github--Local


Figure 452. A Cullen and Frey graph for the $3n+1$ program length data. Data kindly provided by van der Meulen van_der_Meulen_07. Github--Local

Figure 453. Number of
3n+1 programs containing a given number of lines, with four distributions fitted to this data. Data kindly provided by van der Meulen van_der_Meulen_07. Github--Local
Figure 454. A zero-truncated Negative Binomial distribution fitted to the number of features whose implementation took a given number of elapsed workdays; first 650 days used. Data kindly provided by 7digital 7Digital_12. Github--Local



Figure 457. Density plots of accesses to one article on Slashdot, in minutes since its publication. The distinct Normal distributions (colored and fitted to the log of the data) contained in the mixture models fitted by the
REBMIX (upper) and normalmixEM (lower) functions. Data kindly supplied by Kaltenbrunner Kaltenbrunner_07. Github--Local

Figure 459. Graph of available state transitions for Alaris volumetric infusion pump (the button presses that cause transitions between states are not shown). Data kindly supplied by Oladimeji Oladimeji_08. Github--Local

Figure 460. Discrete-time Markov chain for created/modified/deleted status of Linux kernel files at each major release from versions 2.6.0 to 2.6.39. Data from Tarasov Tarasov_12. Github--Local

Figure 461. Directed graph of emails between FreeBSD and OpenBSD developers, plus a few people involved in both discussions, with developers who sent/received less than four emails removed. Data from Canfora et al Canfora_11. Github--Local

Statistics




Figure 466. Power consumed by three SERT benchmark programs at various levels of system load; crosses at 2% load intervals, lines based on 10% load intervals. Data kindly provided by Kistowski Kistowski_15. Github--Local







Figure 473. Number of commits to glibc for each day of the week, for the years from 1991 to 2012. Data from González-Barahona et al Gonzalez-Barahona_14. Github--Local







Figure 481. Density plot of two samples; samples either drawn from a Normal distribution or a Contaminated Normal distribution (i.e., values drawn from two normal distributions, with 10% of values drawn from a distribution having a standard deviation five times greater than the other); the lines bounding the 95% quartile identify the color used for each plot. Github--Local


Figure 483. Regression model (red line; pvalue=0.02) fitted to the number of correct/false security code review reports made by 30 professionals; blue lines are 95% confidence intervals. Data from Edmundson et al Edmundson_13. Github--Local

Figure 484. Bootstrapped regression lines fitted to random samples of the number of correct/false security code review reports made by 30 professionals. Data from Edmundson et al Edmundson_13. Github--Local



Figure 487. Number of Reflection benchmark results achieving a given score, reported for GTX 970 cards from three third-party manufacturers. Data extracted from UserBenchmark.com. Github--Local

Figure 488. Density plots of project bids submitted by companies before/after seeing a requirements document. Data from Jørgensen et al Jorgensen_04c. Github--Local

Figure 489. Density plot of task implementation estimates: with no instructions (red) and with instruction on what to do (blue). Data from Jørgensen el al Jorgensen_04. Github--Local


Regression modeling
Figure 492. Relationship between data characteristics (edge labels) and applicable techniques (node labels) for building regression models.

Figure 493. Total lines of source code in FreeBSD by days elapsed since the project started (in 1993). Data from Herraiz Herraiz_08. Github--Local

Figure 494. Estimated cost and duration of 73 large Dutch federal IT projects, along with fitted model and 95% confidence intervals (green for the bounds of the fitted line and blue for the bounds of any new measurements). Data from Kampstra et al Kampstra_09. Github--Local


Figure 496. Number of commits made, and the number of contributing developers for Linux versions 2.6.0 to 3.12. The blue line in the right plot is the regression model fitted by switching the x/y values. Data from Kroah-Hartman Kroah-Hartman_14. Github--Local

Figure 497. Effort/Size of various projects and regression lines fitted using Effort as the response variable (red, with green 95% confidence intervals) and Size as the response variable (blue). Data from Jørgensen et al Jorgensen_03. Github--Local

Figure 498. Lines of code in every initial release (i.e., excluding bug-fix versions of a release) of the Linux kernel since version 1.0, along with fitted straight line (upper) and quadratic (lower) regression models. Data from Israeli et al Israeli_10. Github--Local

Figure 499. Actual (left of vertical line), and predicted (right of vertical line) total lines of code in Linux at a given number of days since the release of version 1.0, derived from a regression model built from fitting a cubic polynomial to the data (dashed lines are 95% confidence bounds). Data from Israeli et al Israeli_10. Github--Local



Figure 502. Percentage of vulnerabilities detected by developers who have worked a given number of years in security. Data extracted from Edmundson et al Edmundson_13. Github--Local





Figure 507. Number of medical devices reported recalled by the US Food and Drug Administration, in two week bins; fitted straight line and confidence bounds, with loess fit (yellow). Data from Alemzadeh et al Alemzadeh_13. Github--Local


Figure 509. Two fitted straight lines and confidence intervals, one up to the end of 2010 and one after 2010. Data from Alemzadeh et al Alemzadeh_13. Github--Local



Figure 512. Anscombe data sets with Pearson correlation coefficient, mean, standard deviation, and line fitted using linear regression. Data from Anscombe Anscombe_73. Github--Local

Figure 513. Residual of the straight line fit to the Linux growth data analysed in figure. Data from Israeli et al Israeli_10. Github--Local



Figure 516. Change-points detected by
cpt.mean, upper using method="AMOC" and lower using method="PELT". Data from Alemzadeh et al Alemzadeh_13. Github--Local
Figure 517. Fitted regression model (blue) and adjusted model with one change-point (red). Data from Alemzadeh et al Alemzadeh_13. Github--Local



Figure 520. Author workload against number of activity types per author (upper) and ratio test (lower). Data from Vasilescu et al Vasilescu_12. Github--Local


Figure 522. Number of vulnerabilities detected by professional developers with web security review experience; upper: technically correct plot of model fitted using a Poisson distribution, lower: simpler to interpret curve representation of fitted regression models assuming measurement error has a Poisson distribution (continuous lines), or a Normal distribution (dashed lines). Data extracted from Edmundson Edmundson_13. Github--Local

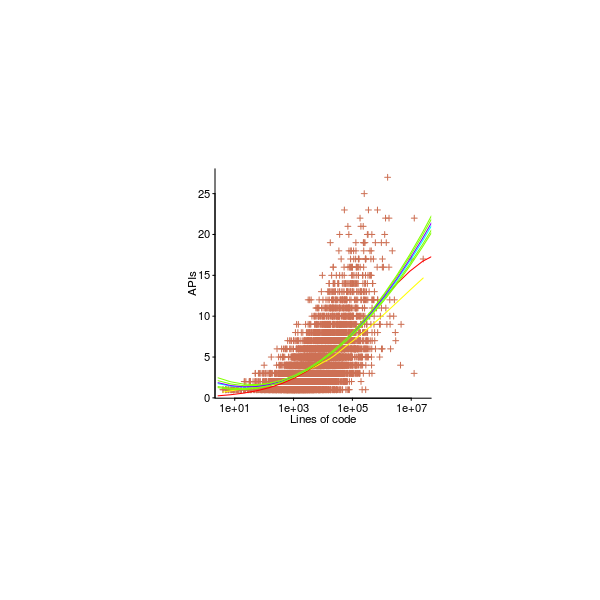


Figure 526. Annual development cost and lines of Fortran code delivered to the US Air Force between 1962 and 1984; lines show fitted regression models (red: log transformed, blue: using a log link function) before(solid)/after(dotted) outlier removed (circled in red). Data extracted from NeSmith NeSmith_86. Github--Local

Figure 527. Maintenance task effort and lines of code added+updated, with fitted regression model (red), and SIMEX adjusted for estimated 10% error (blue). Data from Jørgensen Jorgensen_95. Github--Local



Figure 530. Probability of subject response being within a given percentage interval, based on their response to question q31. Data kindly provided by Luthiger Luthiger_07 . Github--Local

Figure 531. Percentage of mutants killed at various percentage of path coverage for 300 or so Java projects; fitted Beta regression (red), with 95% confidence intervals (blue) and
glm (green) regression models. Data from Gopinath et al Gopinath_14. Github--Local




Figure 536. Estimated and actual effort broken down by communication frequency, along with individually fitted straight lines. Data from Moløkken-Østvold et al Molokken_Ostvold_07. Github--Local


Figure 538.
pairs plot of lines added/modified/removed, growth and number of files and total lines in versions 2.6.0 through 3.9 of the Linux kernel. Data from Kroah-Hartman Kroah-Hartman_14. Github--Local

Figure 540. Time to execute a computational biology program on systems containing processors with various L2 cache sizes. Data kindly provided by Hazelhurst Hazelhurst_10. Github--Local

Figure 541. A logistic equation fitted to the lines of code in every non-bugfix release of the Linux kernel since version 1.0. Data from Israeli et al Israeli_10. Github--Local

Figure 542. Predictions made by logistic equations fitted to Linux SLOC data, using subsets of data up to 2900, 3650, 4200 number of days and all days since the release of version 1.0. Data from Israeli et al Israeli_10. Github--Local

Figure 543. Increase in areal density of hard disks entering production over time. Data from Grochowski et al Grochowski_12. Github--Local

Figure 544. Lines of code in the GNU C library against days since 1 January 1990. Data from González-Barahona Gonzalez-Barahona_14. Github--Local

Figure 546. Power law (red) and exponential (blue) fits to feature macro usage in 20 systems written in C; fail to reject p-value for 20 systems is 0.64. Data from Queiroz et al Queiroz_17. Github--Local




Figure 550. Number of files and lines of code in 3,782 projects hosted on Sourceforge; lines are 95%, 50% and 5% quantile regression fits. Data from Herraiz Herraiz_08. Github--Local

Figure 551. Expected maximum number of daily emails to the C++ lib email list expected to occur within a given period of months, with 95% confidence intervals; a GEP fitted model (corresponding
plot function does not provide any user interface options). Data kindly extracted from the WG21 mailing list archive by Roger Orr. Github--Local
Figure 552. The three components of the hourly rate of commits, during a week, to the Linux kernel source tree; components extracted from the time series by
stl. Data from Eyolfson et al Eyolfson_11. Github--Local
Figure 553. Autocorrelation of number of defects found on a given day, for development project C. Data kindly provided by Buettner Buettner_08. Github--Local




Figure 557. Number of features started for each day and fitted regression trend line (upper) and number of features after subtracting the trend (lower). Data kindly supplied by 7Digital 7Digital_12. Github--Local

Figure 558. Autocorrelation (upper) and partial autocorrelation (lower) of the number of features started on a given day (after differencing the log transformed data), over the entire period of the 7digital data. Data kindly supplied by 7Digital 7Digital_12. Github--Local




Figure 562. Cross correlation of feature release “size” (upper non-bugfix releases, lower all releases) and date when bugs are prioritised. Data kindly supplied by 7Digital 7Digital_12. Github--Local

Figure 563. Cross-correlation of source lines added/deleted per week to the glibc library. Data from González-Barahona Gonzalez-Barahona_14. Github--Local


Figure 565. Visualization of alignment between lines of code, in NetBSD’s (blue) and FreeBSD’s (red) first 100 weeks. Data from Herraiz Herraiz_08 Github--Local




Figure 569. The Kaplan-Meier curve for survivability of new releases: (blue) ETPs using only official APIs, (blue) ETPs calling internal APIs (red); dotted lines are 95% confidence intervals. Data from Businge Businge_13. Github--Local

Figure 570. The Kaplan-Meier curve for survivability of ETPs ability to be built using SDK released in subsequent years: (blue) ETPs using only official APIs, (red) ETPs calling internal APIs; dotted lines are 95% confidence intervals. Data from Businge Businge_13. Github--Local



Figure 573. Cumulative incidence curves for problems reported by the splint tool in Samba and Squid (time is measured in number of snapshot releases). Data from Di Penta et al Di_penta_09. Github--Local

Figure 574. Rose diagram of number of commits in each 3-hour period of a day for Linux and FreeBSD. Data from Eyolfson et al Eyolfson_11. Github--Local




Figure 578. Number of commits (upper) and number of commits in which a fault was detected (lower) by hour of day of the commit, for Linux. Data from Eyolfson et al Eyolfson_14. Github--Local

Figure 579. Number of non-fault related commits, and commits related to fixing a reported fault, per hour for weekdays, for linux; with fitted models. Data from Eyolfson et al Eyolfson_14. Github--Local

Figure 580. Number of commits per hour for each weekday, fitted using $\cos(\ldots\cos\ldots)$ (upper), and $\cos(\ldots\cos+\sin\ldots)$ (lower), for Linux; in both cases the fitted fault model (red) has been rescaled to allow comparison. Data from Eyolfson et al Eyolfson_14. Github--Local

Figure 581. Lines of source against percentage test coverage achieved by both Human & Dynodroid tests, only by Dynodroid tests and only by Human tests, for each of the 50 applications. Data from Machiry et al Machiry_13. Github--Local

Figure 582. Ternary plot composed from source lines covered by both Human & Dynodroid tests, by only by Dynodroid tests and only by Human tests (measurements in blue); fitted regression line (green) and prediction points (red) for various total source lines (numeric values). Data from Machiry et al Machiry_13. Github--Local
Miscellaneous techniques


Figure 584. Top levels of the decision tree fitted to the reopened fault data (overly long lines are names of people who reported and fixed the fault). Data from Shihab et al Shihab_10a. Github--Local







Experiments

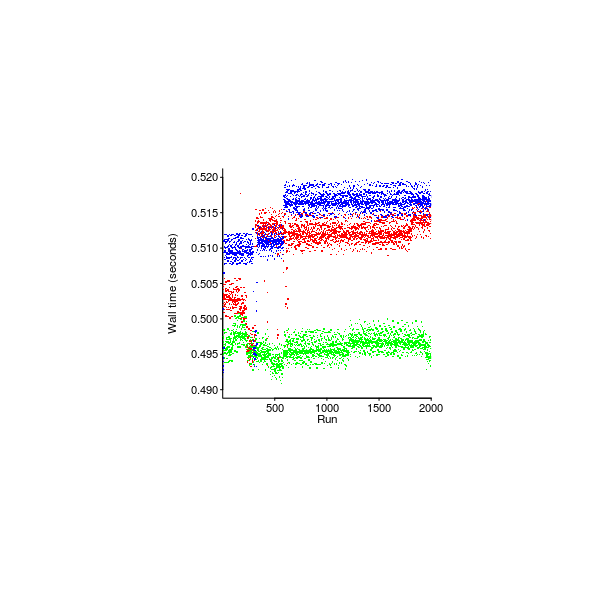
Figure 593. Time taken by 2,000 runs of a Javascript BinaryTree benchmark, with JIT enabled, on a quad-core Intel i7-4790; three colors are three iterations of the process: reboot machine, execute 2,000 runs. Data from Barrett et al Barrett_16. Github--Local




Figure 597. A cube plot of three configuration factors and corresponding benchmark results (blue) from Memory table experiment. Data from Citron et al Citron_03b. Github--Local

Figure 598. Design plot showing the impact of each configuration factor on the performance of Memo table on benchmark performance. Data from Citron et al Citron_03b. Github--Local

Figure 599. Interaction plot showing how
cint changes with size, for given values of mapping. Data from Citron et al Citron_03b. Github--Local
Figure 600. Half-normal plot of data from a Plackett and Burman design experiment. Data from Debnath et al Debnath_08. Github--Local


Figure 602. Feature size, in Silicon atoms, of microprocessors; line is a fitted regression of the form: $\mathit{Silicon{_}atoms}\propto e^{-0.17\mathit{Year} }$. Data from Danowitz et al Danowitz_12. Github--Local




Figure 606. Power consumed by an Exynos-7420 A53 processor at various frequencies, and one to four cores under load, with fitted regression lines. Data kindly provided by Frumusanu Frumusanu_15. Github--Local


Figure 608. Time taken to execute the EP benchmark and clock frequency of 2,386 Intel processors, with a RAPL of 65 Watts. Data kindly provided by Rountree Marathe_17. Github--Local

Figure 609. Power spectrum of the electrical power consumed by the Botanica App executing on a BeagleBone Black running Android 4.2.2. Data from Saborido et al Saborido_15. Github--Local


Figure 611. Average power consumed by one server’s CPU (four Pentium 4 Xeons; red) and memory (8 GB PC133 DIMMs; blue) running the SPEC CPU2006 benchmark (upper) and breakdown by system component when executing various programs. Data from Bircher Bircher_10. Github--Local


Figure 613. FFT benchmark executed 2,048 times followed by system reboot, repeated 10 times. Data kindly provided by from Kalibera_05. Github--Local

Figure 614. Percentage change, relative to no environment variables, in perlbench performance as characters are added to the environment. Data extracted from Mytkowicz et al Mytkowicz_08. Github--Local






Figure 620. Percentage change in SPEC number, relative to version 4.0.4, for 12 programs compiled using six different versions of gcc (compiling to 64-bits with the
O3 option). Data from Makarow Makarow_14. Github--Local
Figure 621. Execution time of the
xy file compressor, compiled using gcc using various optimization options, running on various systems (lines are mean execution time when compiled using each option). Data kindly supplied by Petkovich de_Oliveira_13. Github--Local
Figure 622. Execution time of Perlbench, part of the SPEC benchmark, on six systems, when linked in three different orders and address randomization on/off. Data kindly supplied by Reidemeister de_Oliveira_13. Github--Local


Figure 624. Performance of PassMark memory benchmark on 783 Intel Core i7-3770K systems; line is fitted $\logit$ model. Data kindly supplied by Wren PassMark_14. Github--Local


Figure 626. Probability that a subject, having a given relative ability, will answer a question correctly: lines are for each question in a fitted Rasch model. Data from Dietrich et al Dietrich_14. Github--Local
Data preparation

Figure 627. Reported LOC and duration of 2,751 code reviews, for one company; reported reviews lasting less than 30 seconds (below green line), involving more than 2,000 LOC (to right of red line), processing at a rate greater than 1,500 LOC per hour (above blue line). Data extracted from Cohen et al Cohen_12. Github--Local

Figure 628. Screen height and width reported by 682,000 unique devices that downloaded an App from OpenSignal in 2015 (upper), reported measurements ordered so height always the larger value (lower). Data from OpenSignal OpenSignal_15. Github--Local


Figure 630. Estimated staff working on a project during each week; lines are a fitted loess model and 95% confidence bounds. Data from Buettner Buettner_08. Github--Local

Figure 631. Market share of Firefox version 3.0 fitted using loess regression with various values of the
span option. Data from W3Counter W3Counter_14. Github--Local

Figure 633. Number of processes executing for a given amount of time, with measurements expressed using two and six significant digits. Data from Feitelson Feitelson_14. Github--Local

